传统的计算机行业的运维方式
传统的计算机行业的运维方式,大部分都是采用系统管理员的模式。大家最熟悉的运维方式是这样:招聘一些系统管理员,他们有负责采购机器的,有负责维护数据中心的,也有专门维护数据库的等等。系统管理员模式有几个特点,他们只是把一些现成的组件组装起来,并不会自己开发和创造新的系统,比如拿了MySQL把它跑起来,或是研发部门开发出来的新代码组装成之后提供这样一个服务。这是运维部门的一个特色,负责把这个东西运行好。
运维部门的职责包括哪些呢?
最重要的是应急事件的处理,这是重中之重,也是最唯一的职责。其次是常规更新,现在的业务发展越来越快,每周都有新的东西上线,比如说今天要买新机器,明天要改IP地址,大家可能80%的投入都是在这些事上,这就是系统管理员或者是现在运维行业的工作模式。
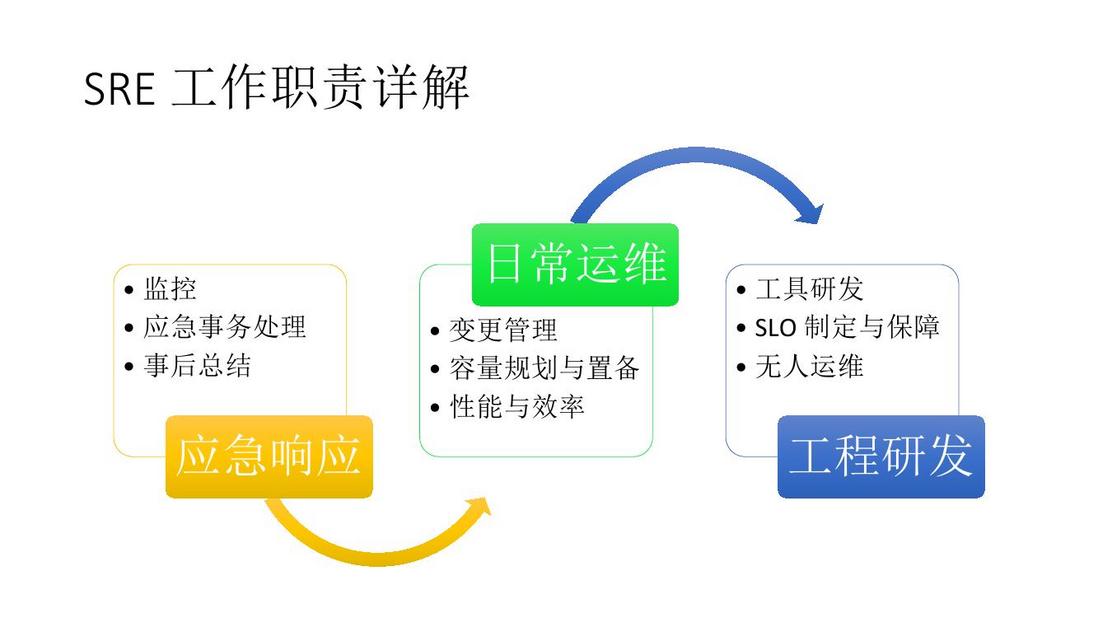
第一类,运维部门最重要的是应急响应这个问题,因为业务越来越大,与运营的结合越来越紧密,很多时候要处理的事情更多的是商业和运营上的事,也包括软件上的问题,这个部门最特殊或者最唯一的职责就是应急响应。之上是日常运维,保证机器能够正常更新、快速迭代。再往上是输出一些工程研发,无论是做工具,还是做高可用架构、提高可靠性,这些都是最上层的东西,只有把底下全部做好了才能说到上面。
SRE的大特点
SRE的一大特点就是想请假的时候随时请假,每一个人都可以请假;当出现紧急情况的时候,当天值班的人真的可以处理他负责的这个服务所有的问题。
SRE所有人都要非常了解整个监控系统在所有业务中的部署实施,其实这是我们平时花精力最多的地方。监控系统里面对整个系统所有方面都有监控,不光包括业务指标,也包括性能指标、效率指标。监控应该平台化、系统化,不停的往上积累,多做一些模板,同质化的系统就可以用同样的方法去做监控。
容量规划: 当规模大到一定程度的时候,就需要有人来回答这个问题——到底要买多少新机器,能否保证明年的性能、效率,那谁来负责这件事呢?SRE部门提出这些方案,然后要确保这些指标、这些东西是有数据支撑的,确实能解决问题的。
SRE在工程研发上主要的工作,首先是帮产品部门确定一个SLO。SLO是一个服务指标,每一个产品都有一个服务指标。任何系统都不可能是百分之百可靠的,也没有必要做到百分之百可靠。这里得有一个目标.
我眼中的运维工作
运维是辛苦的,所以要求你是精英,至少是一当三的好汉(几乎没有女生),系统运维更是如此。但是辛苦不是所有忙的借口,而应该利用工具,利用软件工程思想去自动化当前重复的劳动。有章可循的步骤都是可以自动化的,当然最好是多人做这种,如果你们人很少,那也是你技术飞涨的时候。
运维和其他支持岗位一样,大部分情况吃力不讨好,你工作了1年没犯错年底出了个核心事故可能有kpi完蛋了。但事情从来不应该怪在人身上,而是让平台去规避犯错,平台化运维是走向运维自动化的核心一步。
运维也需要大量的沟通,这里面有你的上司,同事,其他部门的可爱同事,机房等等。很多公司是通过工单case来处理各个产品的日常的,这时候你还要面对无数的产品的人。和人沟通最重要的还是控制自己的情绪(不表现在语言里面),复杂事情通过电话或者当面解决,多换位思考。
运维需要很多开发的支持。如果你们运维开发给力当然没有这个问题。但是你依然要努力让自己能开发项目,至少熟练两种语言(shell得会吧, python/go/perl)等。因为运维你和全栈工程师只差一个语言了吧。
运维工程师需要很强的专业素养,尤其表现为规划和出事故的时候。如果出事故,你命令都敲不出来,去网上查命令,那可用率完了。这个时候就需要适当地升级,所以一个运维的人应该永远有A/B方案,对每一条命令知道他的后果并且能确保回滚。
运维学习侧重
首先是linux的常用命令和shell编程,这个是你和系统对话的语言
其次是网络支持和tcp/ip协议栈,这个是网络故障排查和部署业务上线web开发排查等的必备知识
了解常见中间组件的使用,系统如果是身体,那么中间件就是好看的衣服,了解它能让你站得更高,比如mysql, tomcat,kafka等
性能调优是在你熟悉代理、网络、系统等命令下,对多个链路组件进行调节,那个时候你就是厉害的人
监控类,你可以了解elk,zabbix,nagios等监控类和日志类组件,如果你研究够深,其他可以再学
如下是一些个人经验:
可以看看google sre,看看一些运维架构方面的分享,学习一些中间件,阅读一些源码,试着掌握一些技术的深层次的东西.